Table Of Content
A data warehouse gathers raw data from multiple sources into a central repository and organizes it into a relational database infrastructure. This data management system primarily supports data analytics and business intelligence applications, such as enterprise reporting. The system uses ETL processes to extract, transform, and load data to its destination. However, it is limited by its inefficiency and cost, particularly as the number of data sources and quantity of data grow over time. An Azure data lake includes scalable, cloud data storage and analytics services.
A dynamic prediction model for prognosis of acute-on-chronic liver failure based on the trend of clinical indicators

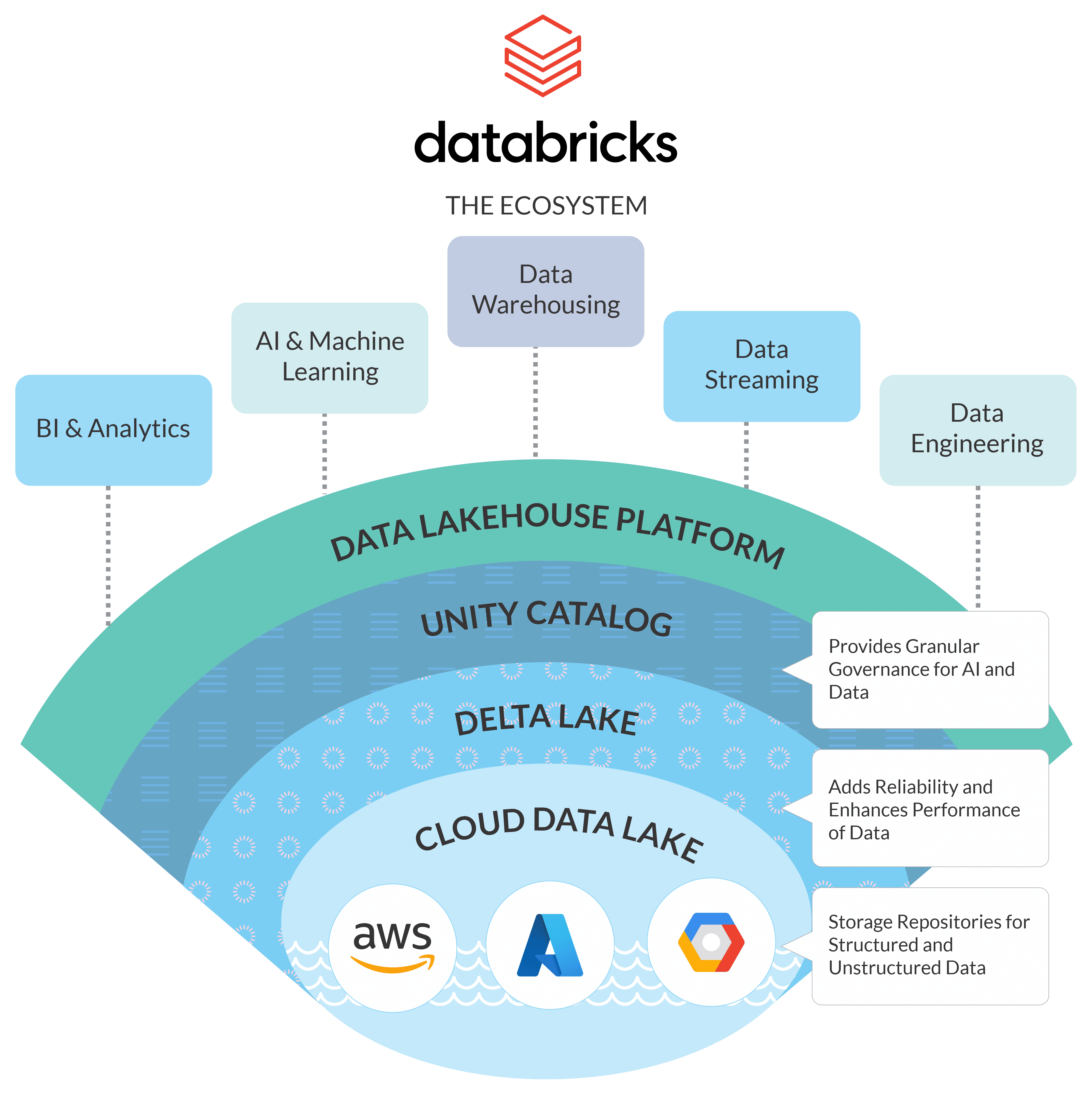
This first layer gathers data from a range of different sources and transforms it into a format that can be stored and analyzed in a lakehouse. The ingestion layer can use protocols to connect with internal and external sources such as database management systems, NoSQL databases, social media, and others. IBM watsonx.data is the industry’s only open data store that enables you to leverage multiple query engines to run governed workloads, wherever they reside, resulting in maximized resource utilization and reduced costs. Modern information technologies such as Internet of Things, big data, and cloud computing have been deployed in the district to advance elderly care. It has formed seven commercial complexes and eight large supermarkets as key players, with a total commercial area of approximately 1.2 million square meters, and annual sales of around 3.5 billion yuan. In addition, Hedong has been upgrading its business transformation to boost consumption and the night-time economy.
LinkedIn Open Sources OpenHouse Data Lakehouse Control Plane - The New Stack
LinkedIn Open Sources OpenHouse Data Lakehouse Control Plane.
Posted: Wed, 06 Mar 2024 08:00:00 GMT [source]
Full Text Sources
Users can implement predefined schemas within this layer, which enable data governance and auditing capabilities. A modern lakehouse architecture that combines the performance, reliability and data integrity of a warehouse with the flexibility, scale and support for unstructured data available in a data lake. This final layer of the data lakehouse architecture hosts client apps and tools, meaning it has access to all metadata and data stored in the lake. Users across an organization can make use of the lakehouse and carry out analytical tasks such as business intelligence dashboards, data visualization, and other machine learning jobs. Modern data lakes leverage cloud elasticity to store virtually unlimited amounts of data "as is," without the need to impose a schema or structure.
Tianjin’s Hedong district: High-quality development in hand with high living standards
Learn about barriers to AI adoptions, particularly lack of AI governance and risk management solutions.
What is the difference between an Azure data lake and an Azure data warehouse?
Cloudera Unveils Next Phase Of Open Data Lakehouse To Unlock Enterprise AI - Datanami
Cloudera Unveils Next Phase Of Open Data Lakehouse To Unlock Enterprise AI.
Posted: Thu, 07 Mar 2024 08:00:00 GMT [source]
A data lake is a central location that holds a large amount of data in its native, raw format, as well as a way to organize large volumes of highly diverse data. Compared to a hierarchical data warehouse, which stores data in files or folders, a data lake uses a flat architecture to store the data. As a result, you can store raw data in the lake in case it will be needed at a future date — without worrying about the data format, size or storage capacity. Data lakes act as a catch-all system for new data, and data warehouses apply downstream structure to specific data from this system.
Key Technology Enabling the Data Lakehouse
The model's performance was evaluated in a validation set of 130 patients from another center. In the training set, multivariate Cox regression analysis revealed that age, WGO type, basic etiology, total bilirubin, creatinine, prothrombin activity, and hepatic encephalopathy stage were all independent prognostic factors in ACLF. We designed a dynamic trend score table based on the changing trends of these indicators. Furthermore, a logistic prediction model (DP-ACLF) was constructed by combining the sum of dynamic trend scores and baseline prognostic parameters. All prognostic scores were calculated based on the clinical data of patients at the third day, first week, and second week after admission, respectively, and were correlated with the 90-day prognosis by ROC analysis.
"In recent years, Hedong has focused on improving the quality and efficiency of development, and optimizing the urban spatial structure." said Han Qiming, head of the district's commerce department. The district has taken advantage of the opportunities brought by the regional coordinated development of Beijing-Tianjin-Hebei. In the first half of the year, the district has introduced 202 projects from Beijing and Hebei based enterprises, with an investment totaling 5.58 billion yuan($862.35 million). We know that many of you worry about the environmental impact of travel and are looking for ways of expanding horizons in ways that do minimal harm - and may even bring benefits.
It supports diverse data datasets, i.e. both structured and unstructured data, meeting the needs of both business intelligence and data science workstreams. It typically supports programming languages like Python, R, and high performance SQL. Data lakes are open format, so users avoid lock-in to a proprietary system like a data warehouse. Open standards and formats have become increasingly important in modern data architectures. Data lakes are also highly durable and low cost because of their ability to scale and leverage object storage. Additionally, advanced analytics and machine learning on unstructured data are some of the most strategic priorities for enterprises today.
Azure Data Lake Storage enables organizations to store data of any size, format and speed for a wide variety of processing, analytics and data science use cases. When used with other Azure services — such as Azure Databricks — Azure Data Lake Storage is a far more cost-effective way to store and retrieve data across your entire organization. Since data lakehouses emerged from the challenges of both data warehouses and data lakes, it’s worth defining these different data repositories and understanding how they differ. Data lakehouses seek to resolve the core challenges across both data warehouses and data lakes to yield a more ideal data management solution for organizations.
This feature is critical in ensuring data consistency as multiple users read and write data simultaneously. Whether your data is large or small, fast or slow, structured or unstructured, Azure Data Lake integrates with Azure identity, management and security to simplify data management and governance. Azure storage automatically encrypts your data, and Azure Databricks provides tools to safeguard data to meet your organization’s security and compliance needs. The advanced cloud-native data warehouse designed for unified, scalable analytics and insights available anywhere. With granular elastic scaling and pause and resume functionality, Netezza Performance Server offers you cost and resource control at a massive enterprise scale.
Next, a small segment of the critical business data is ETLd once again to be loaded into the data warehouse for business intelligence and data analytics. It’s a unified catalog that delivers metadata for every object in the lake storage, helping organize and provide information about the data in the system. This layer also gives user the opportunity to use management features such as ACID transactions, file caching, and indexing for faster query.
Comparative analysis showed that the AUC value for DP-ACLF was higher than for other prognostic scores, including Child-Turcotte-Pugh, MELD, MELD-Na, CLIF-SOFA, CLIF-C ACLF, and COSSH-ACLF. The new scoring model, which combined baseline characteristics and dynamic changes in clinical indicators to predict the course of ACLF, showed a better prognostic ability than current scoring systems. Scale AI workloads for all your data, anywhere, with IBM watsonx.data, a fit-for-purpose data store built on an open data lakehouse architecture. You can easily query your data lake using SQL and Delta Lake with Azure Databricks. Delta Lake enables you to execute SQL queries on both your streaming and batch data without moving or copying your data. Azure Databricks provides added benefits when working with Delta Lake to secure your data lake through native integration with cloud services, delivers optimal performance and helps audit and troubleshoot data pipelines.
The unique ability to ingest raw data in a variety of formats — structured, unstructured and semi-structured — along with the other benefits mentioned makes a data lake the clear choice for data storage. They are known for their low cost and storage flexibility as they lack the predefined schemas of traditional data warehouses. The size and complexity of data lakes can require more technical resources, such as data scientists and data engineers, to navigate the amount of data that it stores. Additionally, since data governance is implemented more downstream in these systems, data lakes tend to be more prone to more data silos, which can subsequently evolve into a data swamp.

No comments:
Post a Comment